
MySQL架构原理
MySQL体系架构
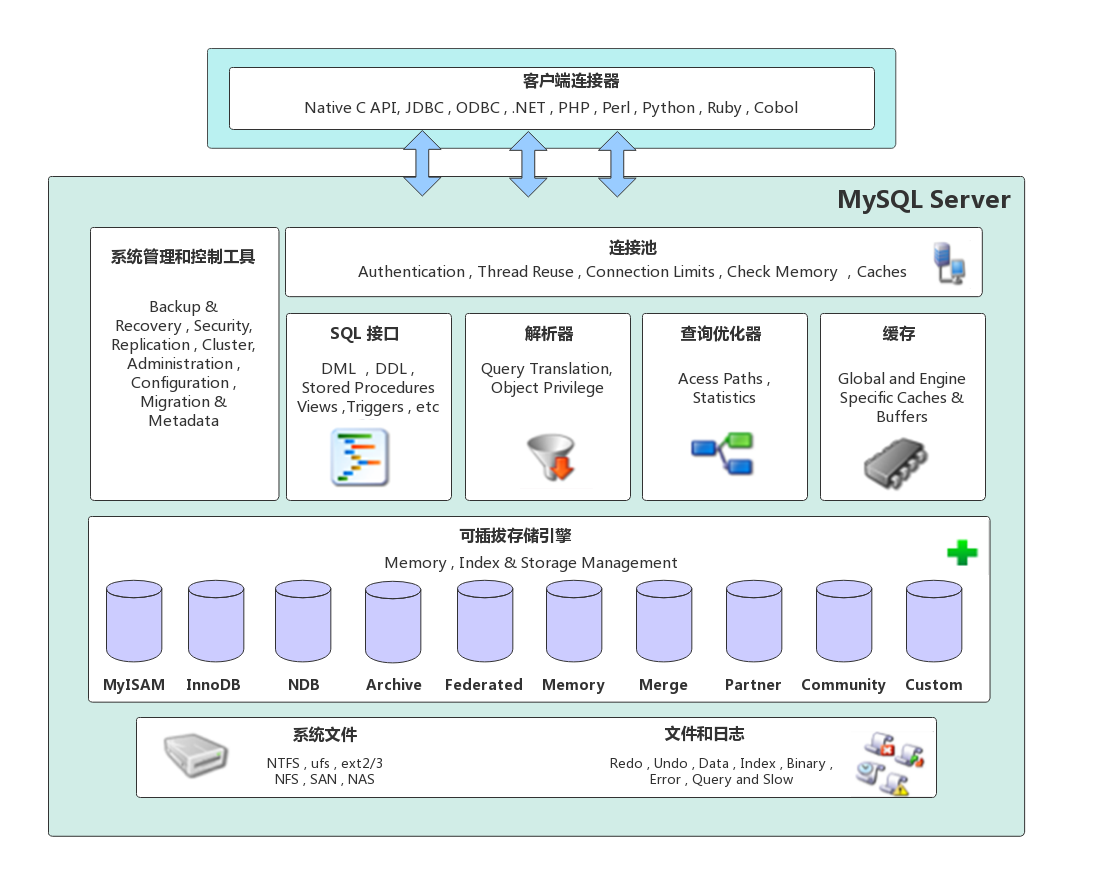
MySQL Server的架构可以分为以下四层:网络连接层、服务层、存储引擎层和系统文件层。
网络连接层
客户端连接器
提供与MySQL服务器连接的支持,支持市面上的主流语言。例如:Java、Python等,它们通过各自的API与MySQL建立连接。
服务层
服务层是MySQL Server的核心,主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优化器、缓存六个部分。
连接池
负责管理与客户端与服务端的连接,一个线程负责管理一个连接。
系统管理和控制工具
备份恢复、安全管理、集群管理等。
SQL接口
用于接收客户端的SQL指令(DDL、DML、存储过程、视图等),返回用户需要的结果信息。
解析器
负责将客户端的SQL指令解析生成一个解析树。然后根据一些SQL规则检查解析树是否合法。
查询优化器
解析树通过解析器的检查后,交由查询优化器来生成执行计划,与存储引擎层进行交互。
缓存
缓存机制是由一系列小缓存组成的:表缓存、记录缓存、权限缓存、引擎缓存等。如果查询命中缓存则可以直接从缓存中获取结果直接返回。
存储引擎层
存储引擎负责MySQL中数据的存储与提取,与系统文件进行交互。MySQL的存储引擎是插件式的。服务器的查询执行通过接口与存储引擎层进行交互,接口屏蔽了不同存储引擎之间的差异。
系统文件层
该层主要负责将数据库的数据和日志存储在文件系统上,并完成与存储引擎的交互,是文件的物理存储层。包括:日志文件、数据文件、配置文件、PID文件、socket文件等。
日志文件
- 错误日志:默认开启,通过
show variables like '%log_error%';查看存储位置 - 通用查询日志:记录一般的查询日志,通过
show variables like '%general%';查看存储位置及开关状态 - 二进制文件(binlog):记录了对MySQL数据库执行的更改操作,并且记录的语句发生时间、执行时长;它不记录SELECT、show等不修改数据库信息的SQL。主要用于数据恢复和主从复制。
show variables like '%log_bin%';//是否开启show variables like '%binlog%';//参数查看show binary logs;//查看日志文件
- 慢查询日志:记录所有查询时长超时的查询SQL,默认10s。
show variables like '%slow_query%';//是否开启show variables like '%long_query_time%';//时长
配置文件
用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
数据文件
- dp.opt:记录整个数据库的默认字符集及排序规则。
- frm文件:存储与表相关的元数据信息,包括表结构的定义信息等;每张表都会有一个自己的frm文件。
- myd文件:MyISAM存储引擎专用。存储MyISAM表的数据,每张表都会有一个MYD文件。
- myi文件:MyISAM存储引擎专用。存储MyISAM表的索引相关信息,每一张表对应一个MYI文件。
- ibd和ibdata文件:存储InnoDB的数据文件(包括索引)。InnoDB存储引擎有两种表空间方式:独享表空间和共享表空间。独享表空间使用ibd文件存储,每张表对应一个ibd文件。共享表空间使用ibdata文件存储,所有表共用一个(或多个,可修改配置)ibdata文件。
- ibdata1文件:系统表空间数据文件,存储表元数据、Undo日志等 。
- ib_logfile0、ib_logfile1 文件:Redo log 日志文件。
PID文件
存放服务器进程的进程ID
socket文件
socket 文件也是在 Unix/Linux 环境下才有的,用户在 Unix/Linux 环境下客户端连接可以不通过 TCP/IP 网络而直接使用 Unix Socket 来连接 MySQL。
MySQL运行机制
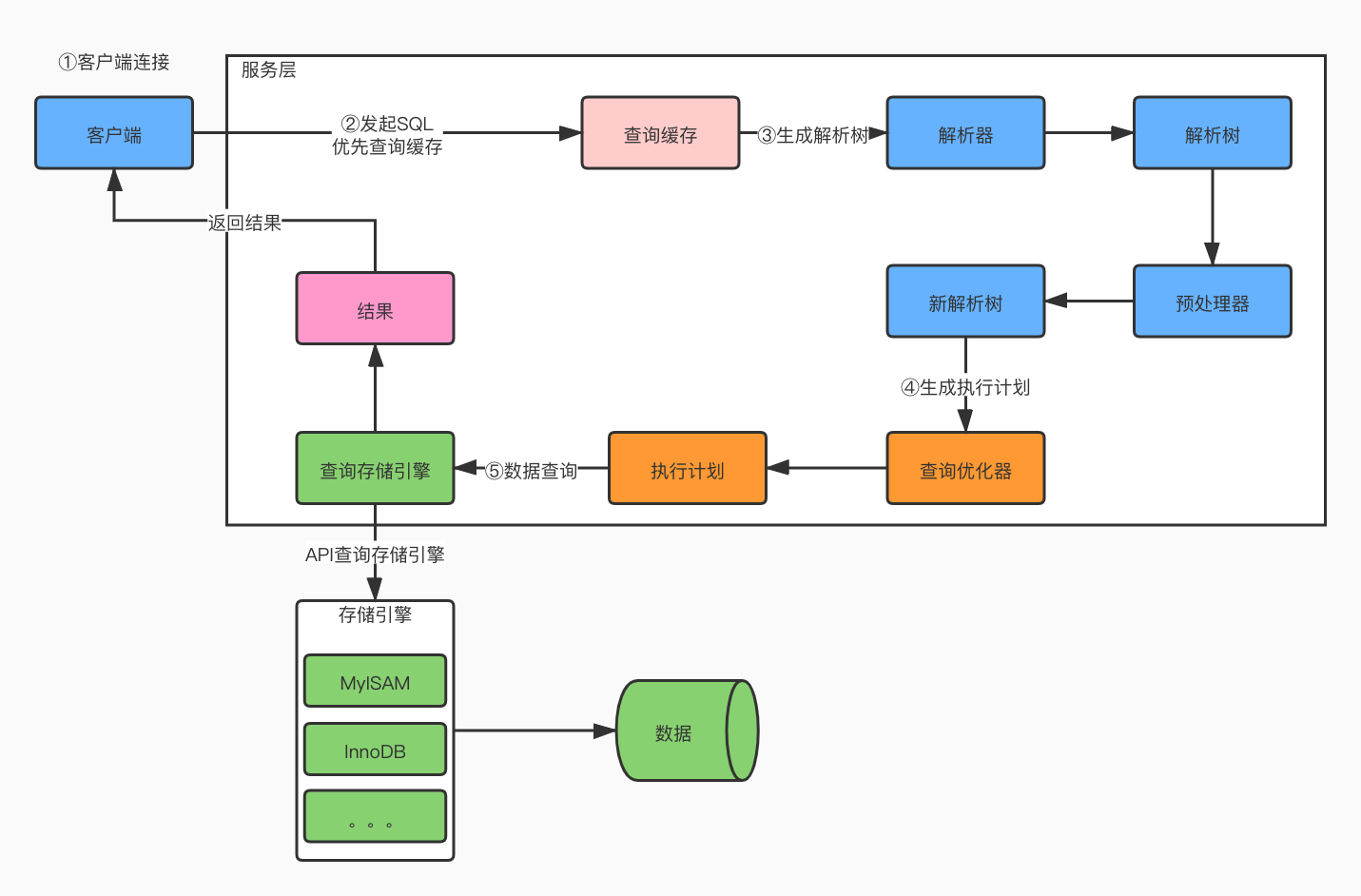
- 建立连接:通过客户端/服务器通信协议与MySQL建立连接,MySQL客户端与服务端的通信方式是半双工,对于每一个客户端的连接,都标记着他们正在做什么。
- 查询缓存:这是MySQL的一个可优化查询的地方,如果开启了查询缓存,且在缓存中存在完全相同的SQL,则将查询结果直接返回给客户端。从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。因为只要该表的结构或者数据被修改,如对该表使用了
INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!select variables like '%query_cache%';查询缓存是否启用、空间大小、限制等。show status like 'Qcache%';查询更详细的缓存参数,可用缓存空间、缓存块、缓存使用大小等。
- 解析器:将客户端发送的SQL进行语法解析,生成解析树;预处理器进一步检查解析树是否合法,例如:数据表和数据列是否存在、名字或者别名是否有歧义;然后生成新的解析树。as单法令jalwekkjadlskjgklajerlkjalksdjlkjfalkejlkajtlkqjwelktjlaalsdjfljasdlfjklajsdfljalalsdkkkekwkwkkwkwjjfjfjfjfaksdjfaljsdl
- 查询优化器:根据生成的解析树生成最优的执行计划。MySQL根据优化策略生成最优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)。
- 等价变换策略:5=5 and a>5 换成 a>5;a = 5 and b<a 换成 a=5 and b<5;基于联合索引调整查询条件顺序;
- 优化 count、min、max函数:InnoDB引擎min函数只需要找索引最左边;InnoDB引擎max函数只需要找索引最右边;MyISAM引擎count(*),不需要计算,直接返回;
- 提前终止查询:使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化:MySQL对in查询,会先进行排序,再采用二分法查找数据。比如:where id in (2,1,3),变 成 where id in (1,2,3)
- 查询执行引擎负责执行 SQL 语句:此时查询执行引擎会根据SQL中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,获得查询结果并返回给客户端。如果开启了查询缓存,会先将查询SQL和查询结果完整的保存到查询缓存中,以后若有相同的查询语句执行则直接将结果在缓存中获取并返回;如果返回结果过多采用增量模式返回;
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Jacian's Blog!
 wechat
wechat alipay
alipay


