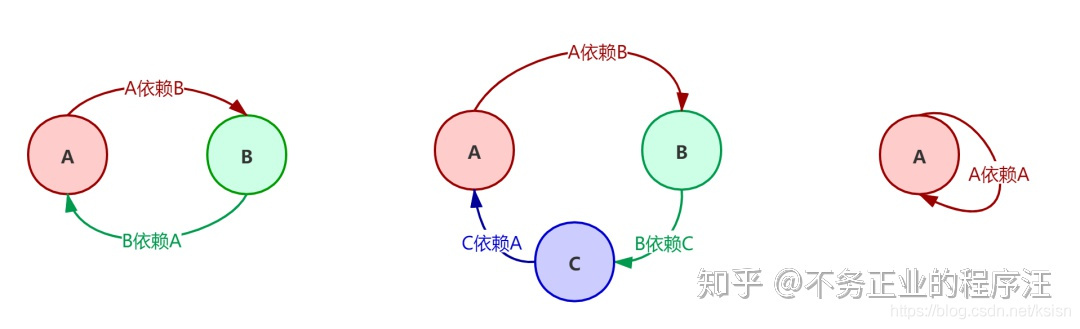
什么是循环依赖? 大家都知道spring的核心是一个实现了AOP的IOC容器,那么IOC容器对于bean的初始化,会遇到以下情况:当BeanA初始化时,它依赖的对象BeanB也需要执行初始化,如果BeanB里也依赖了BeanA,则又会开始执行BeanA的初始化,那么这样会无限循环,导致初始化异常如下所示。
Spring已经很好的解决了这个问题,这个解决方法就是三级缓存。
什么是三级缓存? 我们以上图中A、B互相依赖为例,spring为了解决循环依赖问题,做了以下步骤:
A通过反射创建的“初级bean”a放入到三级缓存中,再执行a的属性填充,这时发现依赖B,开启B的初始化。
B通过反射生成的“初级bean”b放入到三级缓存中,再执行b的属性填充,这时发现依赖A,开启A的初始化。
从三级缓存中找到a,A不再创建新对象,把它移动到二级缓存中,返回a。
b拿到a的引用,设置到b对应的字段上,属性填充完成,将b从三级缓存暴露到一级缓存中,返回b。
a拿到b的引用,设置到a对应的字段上,属性填充完成,将a从二级缓存暴露到一级缓存中,返回a,A对应的实例Bean初始化完成。
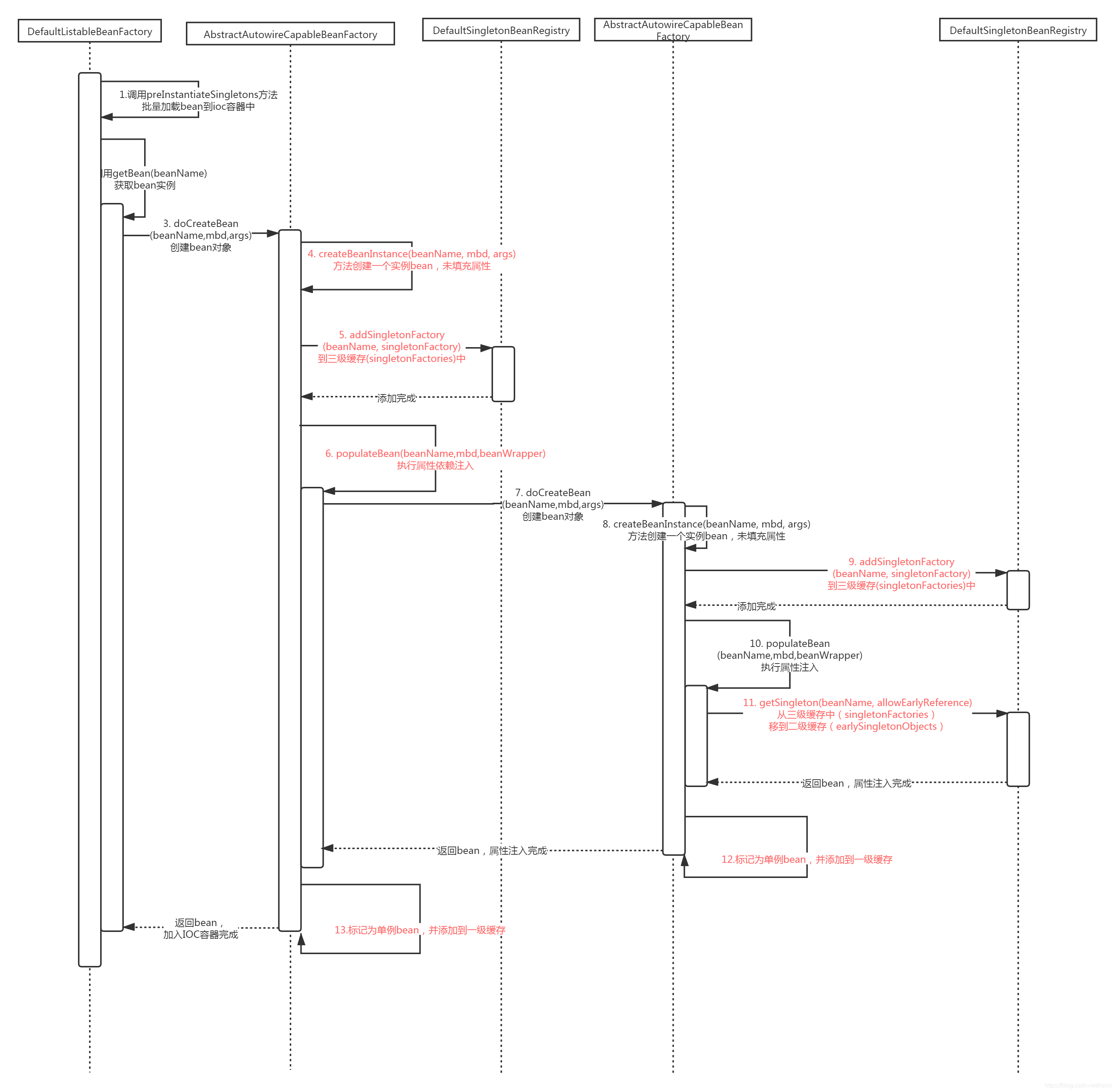
其简易时序图 :
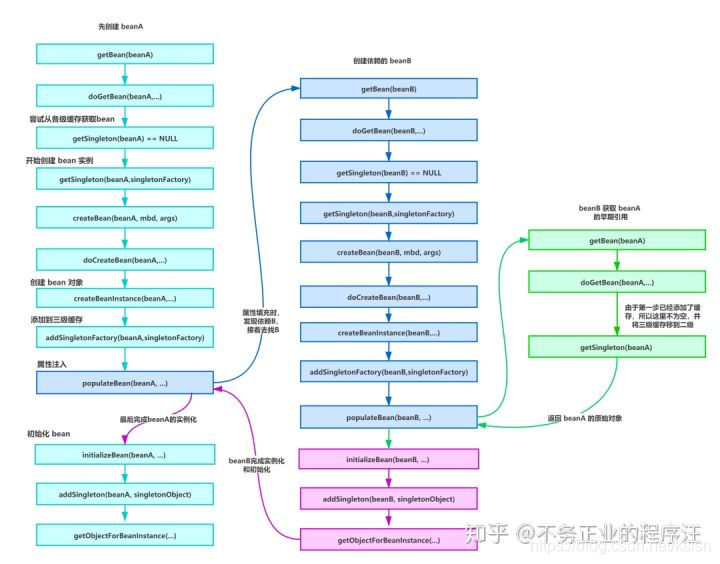
逻辑图如下:
咱们再看看三级缓存的存储结构 :
1 2 3 4 5 6 7 8 9 10 11 12 private final Map<String, Object> singletonObjects = new ConcurrentHashMap <>(256 ); private final Map<String, Object> earlySingletonObjects = new HashMap <>(16 ); private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap <>(16 ); 1234567891011
为什么三级缓存earlySingletonObjects和二级缓存singletonFactories的初始容量16,而一级缓存容量为256呢?笔者认为因为二级、三级仅仅是在处理依赖时会使用到,这种多重循环依赖的情况在实际项目中应该是少数,所以不用使用太大的空间。而最终spring实例化完成的bean会放置在一级缓存中,所以默认容量会调大一些,毕竟spring有很多自身的bean也是放置在这里面的,比如systemEnvironment、systemProperties、messageSource、applicationEventMulticaster等。
spring的源码阅读 当单例对象不存在时,会通过org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String, org.springframework.beans.factory.ObjectFactory<?>)方法来获取单例对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public Object getSingleton (String beanName, ObjectFactory<?> singletonFactory) { synchronized (this .singletonObjects) { Object singletonObject = this .singletonObjects.get(beanName); if (singletonObject == null ) { boolean newSingleton = false ; try { singletonObject = singletonFactory.getObject(); newSingleton = true ; } catch (IllegalStateException ex) { } finally { if (recordSuppressedExceptions) { this .suppressedExceptions = null ; } afterSingletonCreation(beanName); } if (newSingleton) { addSingleton(beanName, singletonObject); } } return singletonObject; } } protected void addSingleton (String beanName, Object singletonObject) { synchronized (this .singletonObjects) { this .singletonObjects.put(beanName, singletonObject); this .singletonFactories.remove(beanName); this .earlySingletonObjects.remove(beanName); this .registeredSingletons.add(beanName); } }
上面代码中的singletonFactory.getObject() 无疑是执行创建的关键代码:
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @Override protected Object createBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException { RootBeanDefinition mbdToUse = mbd; Class<?> resolvedClass = resolveBeanClass(mbd, beanName); if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null ) { mbdToUse = new RootBeanDefinition (mbd); mbdToUse.setBeanClass(resolvedClass); } try { mbdToUse.prepareMethodOverrides(); } catch (BeanDefinitionValidationException ex) { } try { Object bean = resolveBeforeInstantiation(beanName, mbdToUse); if (bean != null ) { return bean; } } catch (Throwable ex) { } try { Object beanInstance = doCreateBean(beanName, mbdToUse, args); return beanInstance; } catch (Throwable ex) { } }
再来看看doCreateBean方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 protected Object doCreateBean (final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args) throws BeanCreationException { BeanWrapper instanceWrapper = null ; if (mbd.isSingleton()) { instanceWrapper = this .factoryBeanInstanceCache.remove(beanName); } if (instanceWrapper == null ) { instanceWrapper = createBeanInstance(beanName, mbd, args); } final Object bean = instanceWrapper.getWrappedInstance(); Class<?> beanType = instanceWrapper.getWrappedClass(); if (beanType != NullBean.class) { mbd.resolvedTargetType = beanType; } boolean earlySingletonExposure = (mbd.isSingleton() && this .allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); if (earlySingletonExposure) { addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); } Object exposedObject = bean; try { populateBean(beanName, mbd, instanceWrapper); exposedObject = initializeBean(beanName, exposedObject, mbd); } catch (Throwable ex) { } if (earlySingletonExposure) { Object earlySingletonReference = getSingleton(beanName, false ); if (earlySingletonReference != null ) { if (exposedObject == bean) { exposedObject = earlySingletonReference; } else if (!this .allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) { } } } try { registerDisposableBeanIfNecessary(beanName, bean, mbd); } catch (BeanDefinitionValidationException ex) { } return exposedObject; }
从doCreateBean方法可以看出:先调用构造方法,生成初级bean,然后暴露到三级缓存,然后执行属性填充,最表标记bean初始化完成,如果二级缓存有,则替换引用,最后完成注册并返回对象。
那么这个填充属性方法populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) 又做了什么呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 protected void populateBean (String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) { PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null ); int resolvedAutowireMode = mbd.getResolvedAutowireMode(); if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) { MutablePropertyValues newPvs = new MutablePropertyValues (pvs); if (resolvedAutowireMode == AUTOWIRE_BY_NAME) { autowireByName(beanName, mbd, bw, newPvs); } if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) { autowireByType(beanName, mbd, bw, newPvs); } pvs = newPvs; } boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors(); boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE); PropertyDescriptor[] filteredPds = null ; if (hasInstAwareBpps) { if (pvs == null ) { pvs = mbd.getPropertyValues(); } for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp; PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { if (filteredPds == null ) { filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { return ; } } pvs = pvsToUse; } } } if (needsDepCheck) { if (filteredPds == null ) { filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } checkDependencies(beanName, mbd, filteredPds, pvs); } if (pvs != null ) { applyPropertyValues(beanName, mbd, bw, pvs); } }
代码比较多,核心思想就是获取这个bean里的所有依赖bean,然后调用applyPropertyValues方法去创建对应的依赖bean,并设置到对应的属性上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 protected void applyPropertyValues (String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) { BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver (this , beanName, mbd, converter); List<PropertyValue> deepCopy = new ArrayList <>(original.size()); boolean resolveNecessary = false ; for (PropertyValue pv : original) { if (pv.isConverted()) { deepCopy.add(pv); } else { String propertyName = pv.getName(); Object originalValue = pv.getValue(); Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue); Object convertedValue = resolvedValue; pv.setConvertedValue(convertedValue); deepCopy.add(pv); } } }
valueResolver.resolveValueIfNecessary方法经过一些的方法,最终调用beanFactory.getBean,这个方法会回到开始进行新一轮的创建bean
1 2 3 4 5 6 7 8 9 10 private Object resolveInnerBean (Object argName, String innerBeanName, BeanDefinition innerBd) { String[] dependsOn = mbd.getDependsOn(); if (dependsOn != null ) { for (String dependsOnBean : dependsOn) { this .beanFactory.registerDependentBean(dependsOnBean, actualInnerBeanName); this .beanFactory.getBean(dependsOnBean); } } }
allowEarlyReference传入true,对于新的bean,已经在三级缓存中存在,会将三级缓存转移到二级缓存,并返回bean,不用真正的去创建一个bean。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 protected Object getSingleton (String beanName, boolean allowEarlyReference) { boolean needWarn = true ; Object singletonObject = this .singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this .singletonObjects) { logger.warn("当前bean已注册,从一级earlySingletonObjects中拿不到->" + beanName + ":" + singletonObject); singletonObject = this .earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { logger.warn("当前bean已注册,从二级缓存earlySingletonObjects中拿不到->" + beanName + ":" + singletonObject); ObjectFactory<?> singletonFactory = this .singletonFactories.get(beanName); if (singletonFactory != null ) { singletonObject = singletonFactory.getObject(); this .earlySingletonObjects.put(beanName, singletonObject); this .singletonFactories.remove(beanName); needWarn = false ; logger.warn("当前bean已注册,从三级singletonFactories中拿到,并移动到二级缓存earlySingletonObjects->" + beanName + " : " + singletonObject); } } } } if (needWarn) { logger.warn("从三级缓存中查询,调用DefaultSingletonBeanRegistry.getSingleton(beanName, allowEarlyReference)->得到" + beanName + ":" + singletonObject + " ,allowEarlyReference:" + allowEarlyReference); } return singletonObject; }
所以第三步的Bean B属性填充方法此时完成,Bean B被加载到一级缓存中。由此回溯,Bean A的属性填充完成,Bean A被加载到一级缓存中。可结合本文最开始给出的时序图进行参考。
其他问题 为什么要用三级缓存而不是二级? 我们可以从三级缓存的值类型看出,一、二级的值均为Spring Bean对象的引用,三级对象则为ObjectFactory的引用。
1 2 3 4 5 6 7 8 9 10 11 private final Map<String, Object> singletonObjects = new ConcurrentHashMap <>(256 ); private final Map<String, Object> earlySingletonObjects = new HashMap <>(16 ); private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap <>(16 );
为什么要有ObjectFactory类型的第三级缓存? 将对象从三级缓存singletonFactories中移动到二级缓存时,会执行ObjectFactory的getBean方法,再调用到getEarlyBeanReference方法,最终遍历该Bean对应的所有SmartInstantiationAwareBeanPostProcessor进行执行;熟悉spring的朋友们肯定知道,SmartInstantiationAwareBeanPostProcessor是Spring Aop动态代理相关属性处理器。执行后获得一个新的bean,该bean是原bean代理对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); 123456789 protected Object getEarlyBeanReference (String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp; exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName); } } } return exposedObject; }
也就是说,三级缓存 存在的目的就是增强对象,当需要使用spring的aop功能时返回代理对象,如果咱们永远用不到代理对象,三级缓存理论上可以不用。
既然三级缓存为了获取代理对象,只保留一三级缓存、第二级缓存可以不要吗? 理论上可以,只需要两级缓存就可以解决循环依赖的问题,但在处理循环依赖的过程,一级缓存中将可能同时存在完整Spring Bean A 和 半成品Spring Bean B。三级对象getObject之后直接放置到二级,最后再刷到一级,二级到一级这个过程中并无额外的处理。
那么为什么spring要使用三级呢?笔者认为一是为了规范各级缓存职责单一原则,不让一级缓存中出现完整的bean和半成品bean;二是为了避免半成品bean被其他线程获取后进行调用,降低实现的难度。

 wechat
wechat alipay
alipay